图像分类的一般框架
图像分类是涉及计算机视觉、机器学习、模式识别等领域的一项交叉研究,具有广阔的应用前景。一般框架如下图所示,包括图像特征提取、图像特征编码与表示、图像分类与检索。
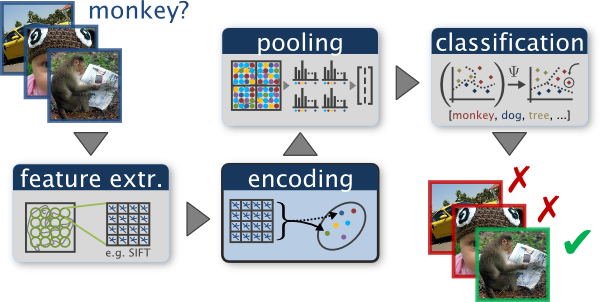
通常图像特征分为全局特征和局部特征,全局特征需要在整幅图像中计算,常用的有全局颜色直方图、功率谱、PHOG等;局部特征计算方式和全局特征方法相反,它首先将图像划分成图像块,再对各个小图像块计算其特征表示,常用的局部特征有GIST、SIFT、SURF、MSER 等。在应用中,由于局部特征鲁棒性好、能够应对多种变换等,因此在分类与识别领域扮演着重要角色。
图像表示是指组织图像特征表达整幅图像或图中目标,当用局部特征表示图像时,由于每幅图像会有很多局部特征,这样特征之间的组织关系就变得十分重要,良好的组织关系使得图像表示更具区分性,并且能捕捉图中目标的结构信息,为后续的分类打好基础。当前比较有代表性的方法包括特征袋(BOW)方法和空间金字塔匹配方法。其中空间金字塔匹配方法又包括基本空间金字塔匹配(Spatial Pyramid Matching, SPM)法、稀疏编码空间金字塔匹配(Sparse coding SPM, ScSPM)法和局部性约束线性编码(Locality-constrained Linear Coding, LLC)空间金字塔匹配法。这几类表示模型也是我们接下来要讨论和评估的。
图像分类里用的最多的是SVM,另外也有衡量不同可视特征对于图像分类重要性的多核学习方法(Multiple Kernel Learning,MKL)。源于自然语言处理主题模型(Topic Model)中的LDA(Latent Dirichlet Allocation)和PLSA(Probabilistic Latent Semantic Analysis)模型也可用于图像分类,该类方法主要是通过图像特征的集合得到隐含的图像主题。与朴素贝叶斯方法相比,LDA和PLSA更适合解决大规模数据的问题。
几种图像表示模型
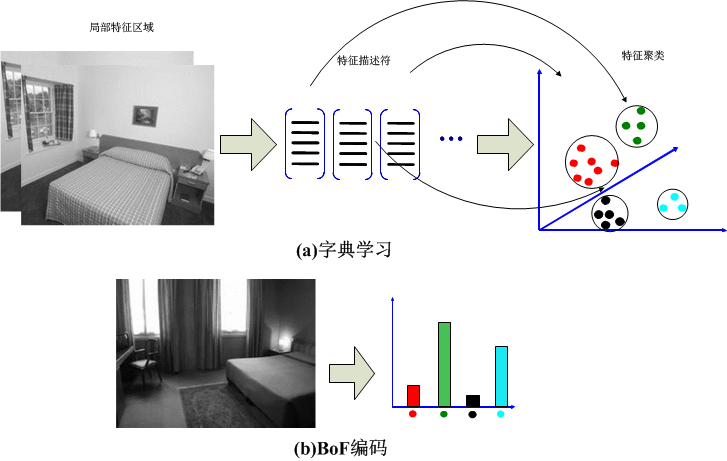
- BOW:
1.局部特征提取与描述;
2.构建大规模、区分力强的视词字典;
3.准确而快速地进行特征向量量化;
4.计算每幅图像的视词直方图;
5.使用TF-IDF策略对视词直方图进行加权。

- SPM:
1.局部特征提取与描述;
2.构建大规模、区分力强的视词字典;
3.准确而快速地进行特征向量量化;
4.计算每个区域的视词直方图组成空间金字塔。
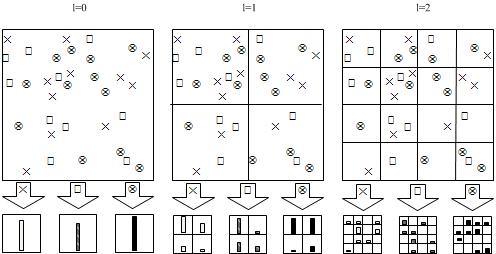
3层空间金字塔
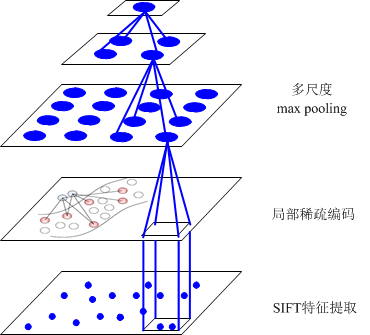
- ScSPM:
1.局部特征提取与描述;
2.学习用于稀疏编码的视词字典;
3.对局部特征进行稀疏编码;
4.对稀疏编码后的特征利用Pooling方法计算空间金字塔。

- LLC:
1.局部特征提取与描述;
2.学习用于稀疏编码的视词字典;
3.对局部特征进行局部约束线性编码;
4.对稀疏编码后的特征利用Pooling方法计算空间金字塔。
图像表示模型性能评估
实验数据集共有15类场景,每一类场景包括200+图像,数据集最初来源于Lazebnik et al. 2006。
在实验中,为了考察不同的参数对实验结果的影响,对于每种参数设置都进行了实验,每个实验随机选择训练集运行10次,最后取精度平均值。
分类器选择线性支持向量机LinearSVM(λ为LinearSVM的则化参数)时的结果:
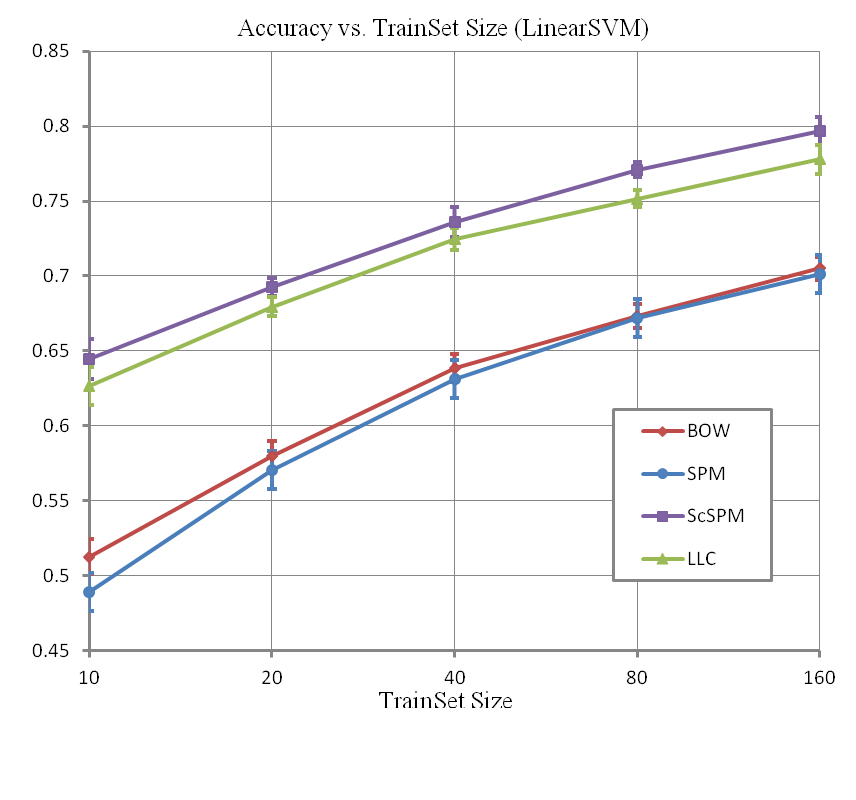

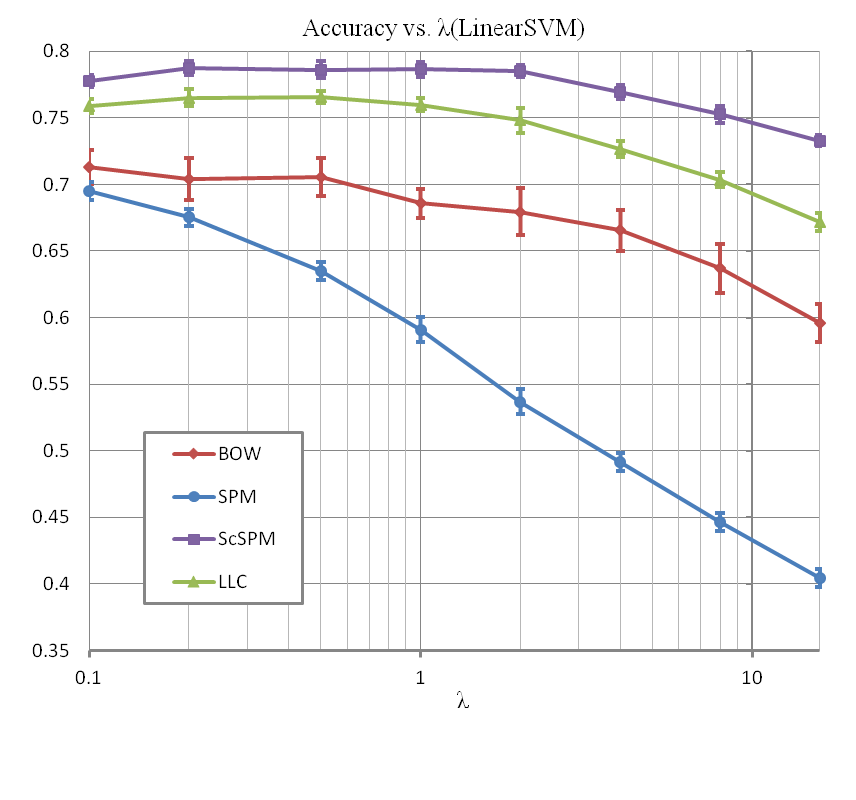
当用非线性SVM(LibSVM库)时,核函数的类型有线性核(Linear)、多项式核(Polynomial)、径向基函数核(RBF)和S型核(Sigmoid),分别为:
* Linear:$u \times v $
* Polynomial:$(gamma \times u \times v)^{degree} $
* RBF:$\exp^{( -gamma \times \abs{u-v}^{2})} $
* Sigmoid:$tanh(gamma \times u \times v + coef) $
非线性SVM只对ScSPM方法进行了实验,结果如下:
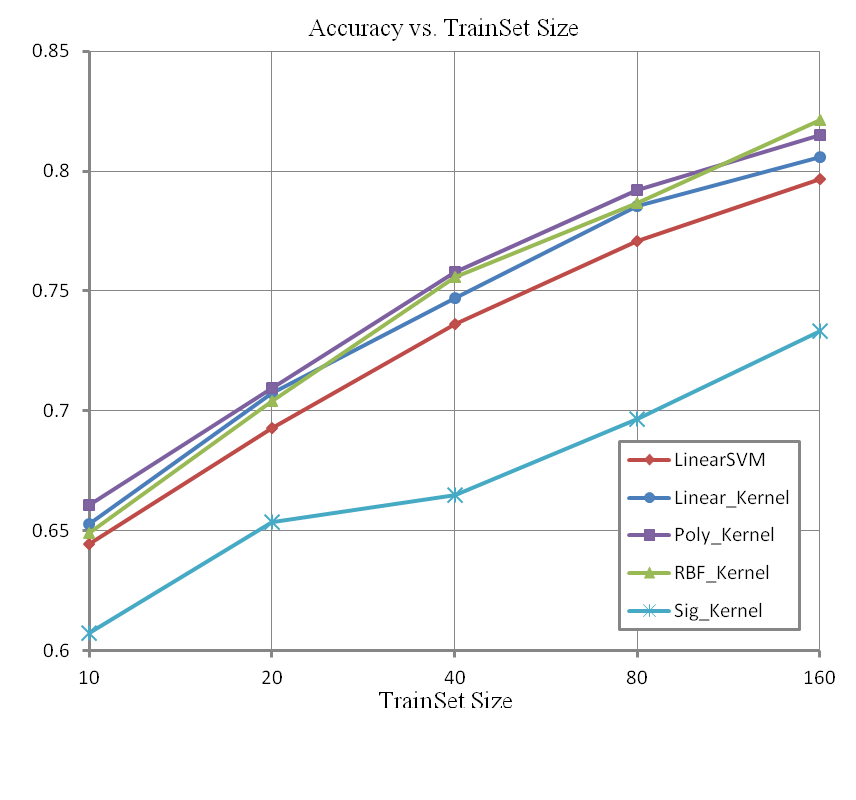
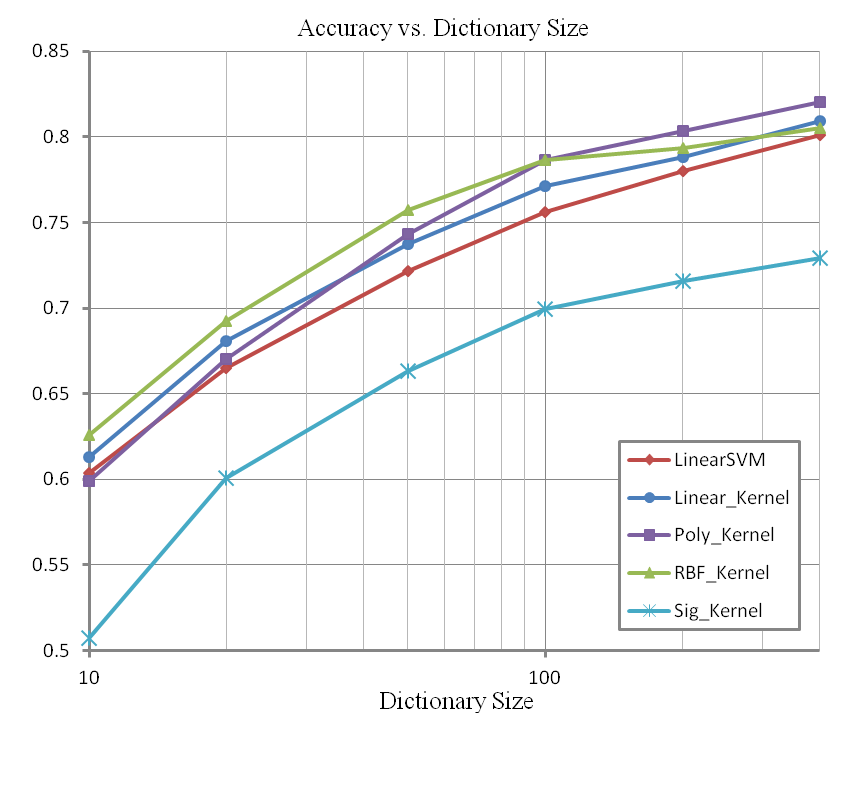
下面是ScSPM图像表示方法下,每类选100幅图像作为训练,在线性SVM分类时的混淆矩阵(右下角处类别的混淆较大,这主要是这些类的图像本来就比较相似):

结论
在所考察的4中表示模型中,ScSPM的方法分类精度是最高的,但是其时间复杂度也比较大,如果对时间要求比较严格,分类精度适当降低可以接受,那么LLC方法是很好的选择。